Load Balancing¶
Clustering services in production environments will enable applications to scale up and achieve high availability. By scaling up, the application can support more user requests and via high availability, the service will be seamlessly available even when a several servers are down. Load balancing is the most straightforward method of scaling out a server infrastructure. Load balancing is the process of efficiently distributing network traffic across multiple servers of a service.
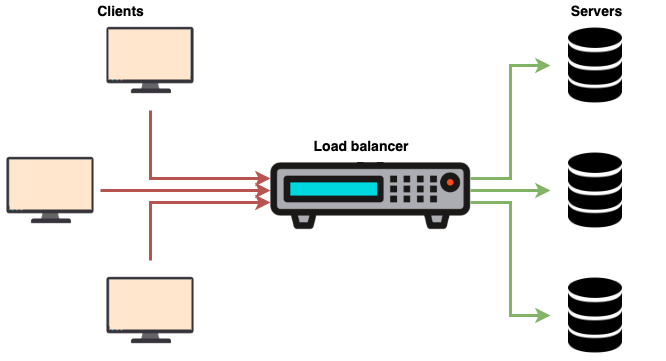
Load Balancer¶
A load balancer can be a device or software which is capable of distributing network traffic across a cluster of servers. Simply, a load balancer acts a cop whose is trying to minimize the traffic in roads. A load balancer sits in between the clients and the servers accepting incoming network traffic and routing those requests backend servers so that minimum traffic is available.
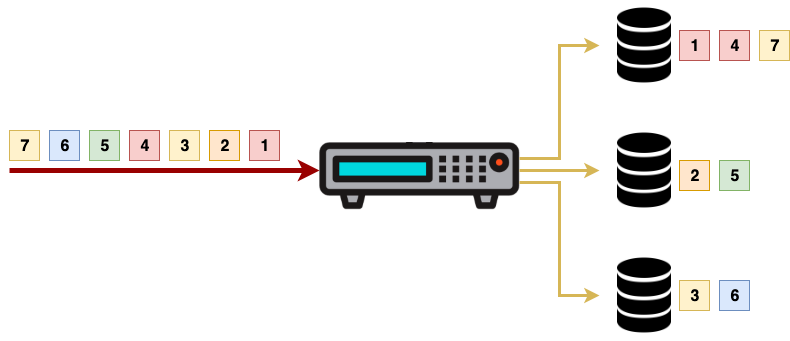 A load balancer to is used to distribute requests among the nodes in a
cluster. The nodes that receive incoming traffic are a set of backend
worker nodes. They can be either,
A load balancer to is used to distribute requests among the nodes in a
cluster. The nodes that receive incoming traffic are a set of backend
worker nodes. They can be either,
- Pre-defined (static) nodes or
- Dynamically discovered nodes.
In the static mode, you won't be able to add any new nodes at runtime since all the set of worker nodes are pre-defined. In dynamic mode, you will be able to add nodes at runtime to the load balancer without knowing the IPs and other connection details.
Types of load balancers¶
Among the many varieties of load balancers are hardware, DNS, transport-level (e.g., HTTP level like Apache Tomcat), and application-level load balancers (e.g., Synapse). High-level load balancers, like application-level load balancers, operate with more information about the messages they route and therefore, provide more flexibility but also incur more overhead. The choice of a load balancer is a trade-off between performance and flexibility.
There are many algorithms or methods for distributing the load between servers. Random or round-robin are simple approaches. More sophisticated algorithms consider runtime properties in the system like the machine's load or the number of pending requests. The distribution can also be controlled by application-specific requirements like sticky sessions. With a reasonably diverse set of users, simple approaches perform as well as complex ones.
Session affinity¶
Stateful applications inherently do not scale well. State replication induces a performance overhead on the system. Instead of deploying stateful applications in a cluster, you can use session-affinity-based load balancing.
Session affinity ensures, when a client sends a session ID, the load balancer forwards all requests containing the session ID to the same backend worker node, irrespective of the specified load balancing algorithm. Before the session is created, the request is dispatched to the worker node that is next-in-line and a session is established with that worker node.
Top