Disaster Recovery Deployment Patterns for WSO2 Identity Server¶
The following disaster recovery mechanism describes an implementation of the generic deployment architecture along with a few suggested modifications that can be done to suit further requirements. The strategy falls in between Cold and Warm deployments in the spectrum, and is based on services provided by Microsoft Azure.
Note
This document only describes how to apply disaster recovery strategies to a WSO2 Identity Server deployment, and does not provide information on how to set up the deployment. For information on how to deploy WSO2 Identity Server, see here.
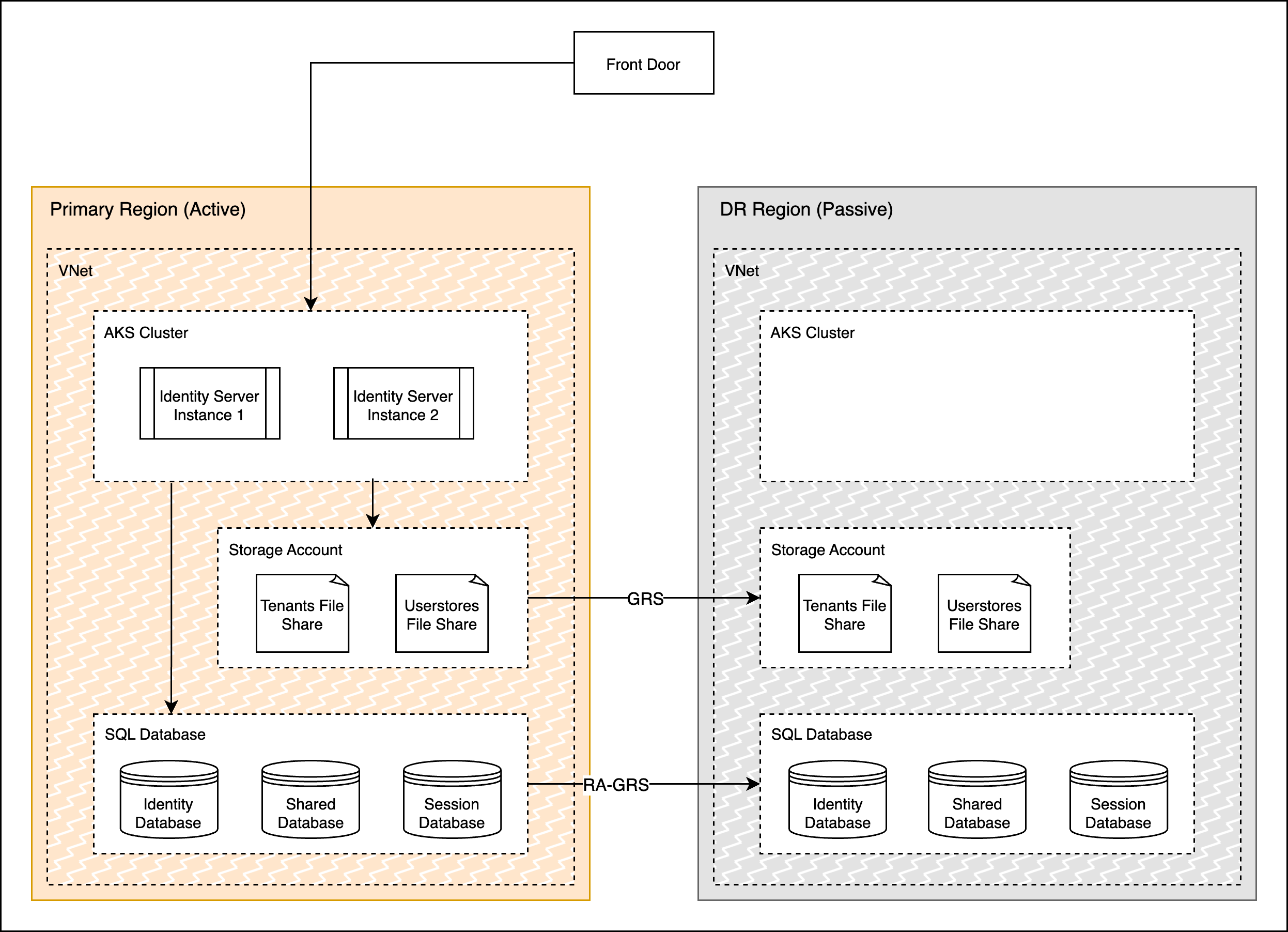
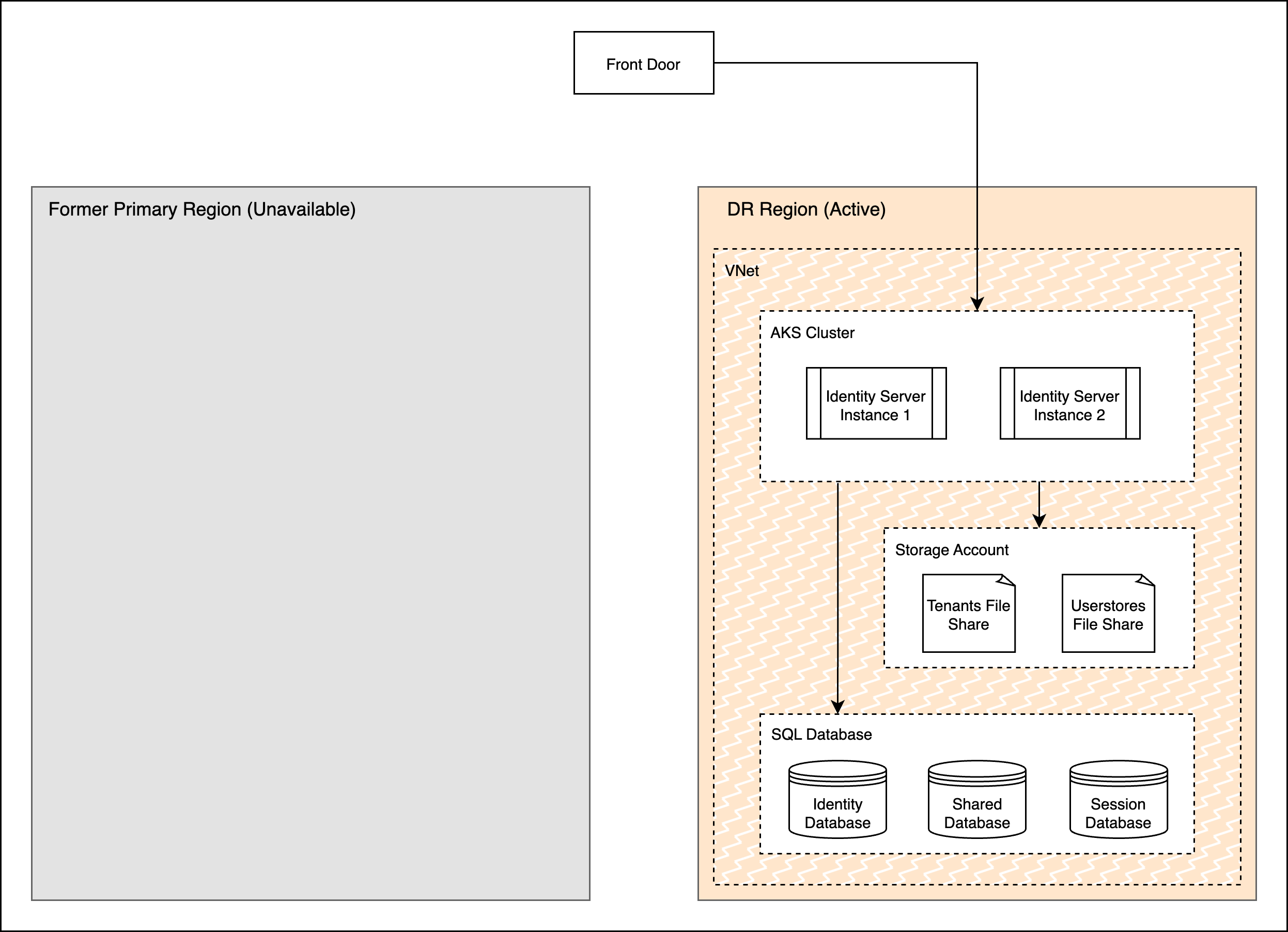
The above diagram depicts the normal operation of the deployment where the primary region actively receives traffic and the data is replicated to the DR passive region. The DR region is running in a relatively cold state, i.e. it is not ready to receive traffic immediately but its data stores will be in sync with the primary. When the Primary region becomes unavailable, the failover mechanism is triggered. The Storage Account and Database in the DR region will be converted to resources with read-write access and the Cluster will be started and scaled up. Finally, the LB will be configured to direct network traffic to the new active region, thus completing the DR pipeline.
Replication Configurations¶
The datastores of WSO2 Identity Server are the databases and file stores, which need to be replicated to the passive region to maintain data consistency between the two regions.
Database Replication¶
Generally, the Identity Server is set up with the Identity and Shared databases only, with the Identity database handling session data as well. Session data gets frequently updated in the database as users continue to interact with applications. Conventional replication methods may not be able to keep up with the high volume of data and that may lead to an uncertain RPO. If a better RPO is required in cases where even frequently updated data (tokens, sessions, etc) need to be replicated immediately with more certainty, other database specific replication services such as Oracle GoldenGate, MySQL Replication, etc, could be set up with prioritized table level replication configured for the more frequently updated tables.
However, it is recommended to configure a separate database to store session data as this provides flexibility to handle the very frequently updated session data. Having replication enabled for such a database will incur very high costs. Therefore, separating out the session database from the identity database, and disabling geo-replication for the session database will help drive down costs. In most cases, it is acceptable for the enterprise to lose end-user logins and sessions, as a downtime involved in switching to a passive data center and providing a user experience without re-login may not be practical.
GRS (RA-GRS) replication offered by general Azure database services replicate data in near real-time, with a lag that depends on the workload and the network latency between the primary and secondary regions. Default replication services can be used for this purpose. Hence, the impact from DB replication on RPO would be minimal, or uncertain in rare cases if there is a high workload or latency. The time taken to convert the secondary region replica to the primary Database with read-write access would be between 5-10 minutes, thereby increasing the RTO by 10 minutes.
File Store Replication¶
File artifacts replication techniques are required to backup the runtime artifacts created when tenants and userstores are generated in the Identity Server. File artifacts replication techniques tend to have adverse impacts on the RPO and RTO as their failover time is generally high, and using custom tools to reduce failover time may increase costs. If the enterprise application is not going to make use of tenants and userstores in the Identity Server, then these replication mechanisms can be disregarded altogether.
GRS replication for File Shares storage accounts can be used to handle the replication of the file system (tenants and userstores). Although RA-GRS is available for the storage account as a whole, only GRS is available for File Shares (i.e. secondary region cannot be read while the primary is active until a failover occurs). But this is not a requirement in this case as this is a Cold DR strategy. File Share replication occurs in near real-time as well, hence the impact on RPO is minimal when the default GRS replication is used. The downside of using File Share replication is that the failover mechanism which converts the replica to the primary could take an hour to complete, which adversely affects the RTO. To address the impact on RTO, a different approach could be followed where the entire storage account is cloned at intervals using an Automation task. This is also the ideal approach to follow in cases where Premium storage is required as it does not offer GRS replication. The Automation task can help to reduce the RTO vastly but it
Deployment Pattern Variations¶
These replication configurations of this deployment can be altered to achieve various combinations of RPO/RTO at different costs.
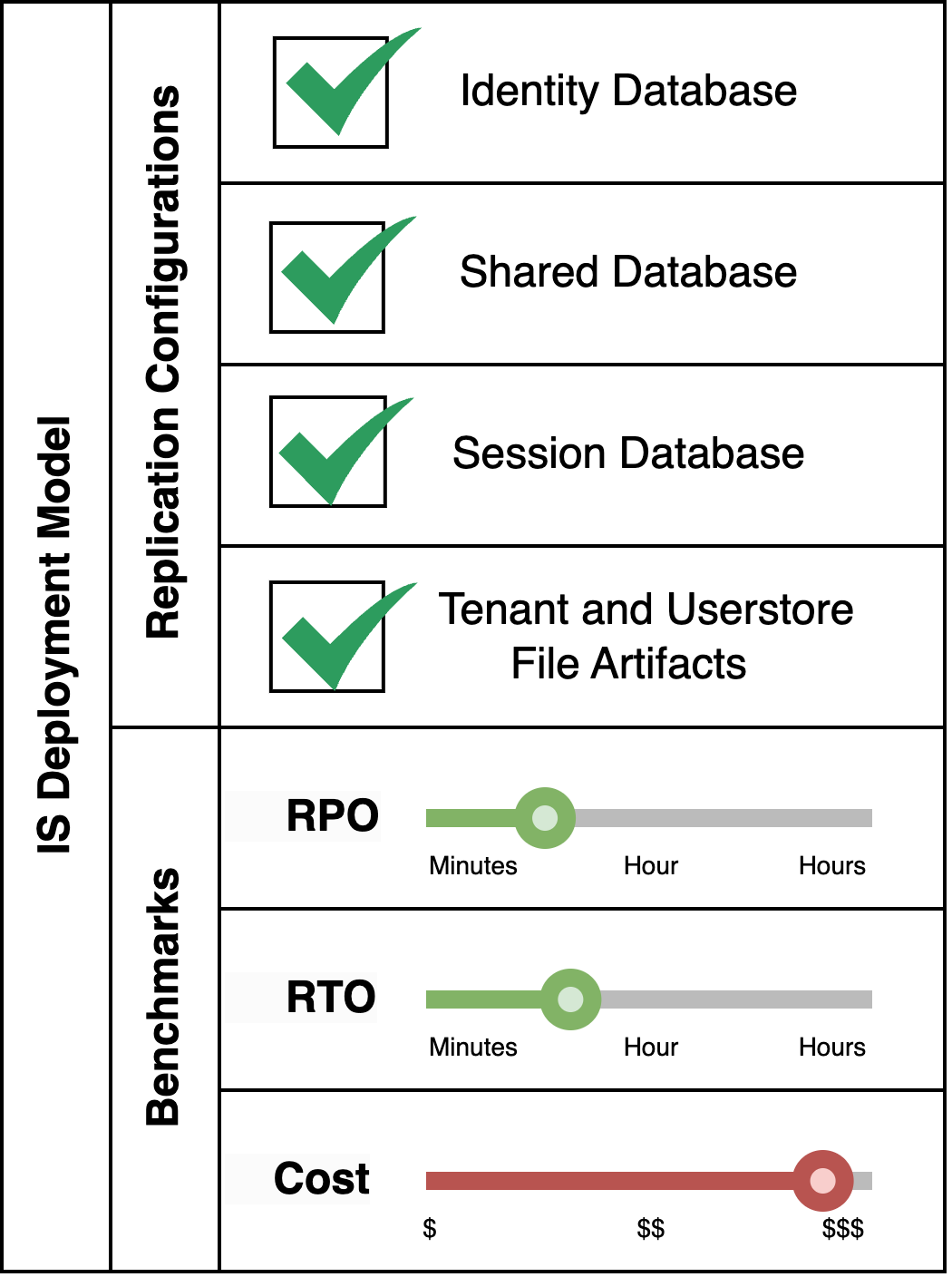
Pattern Variant 1: Total Replication
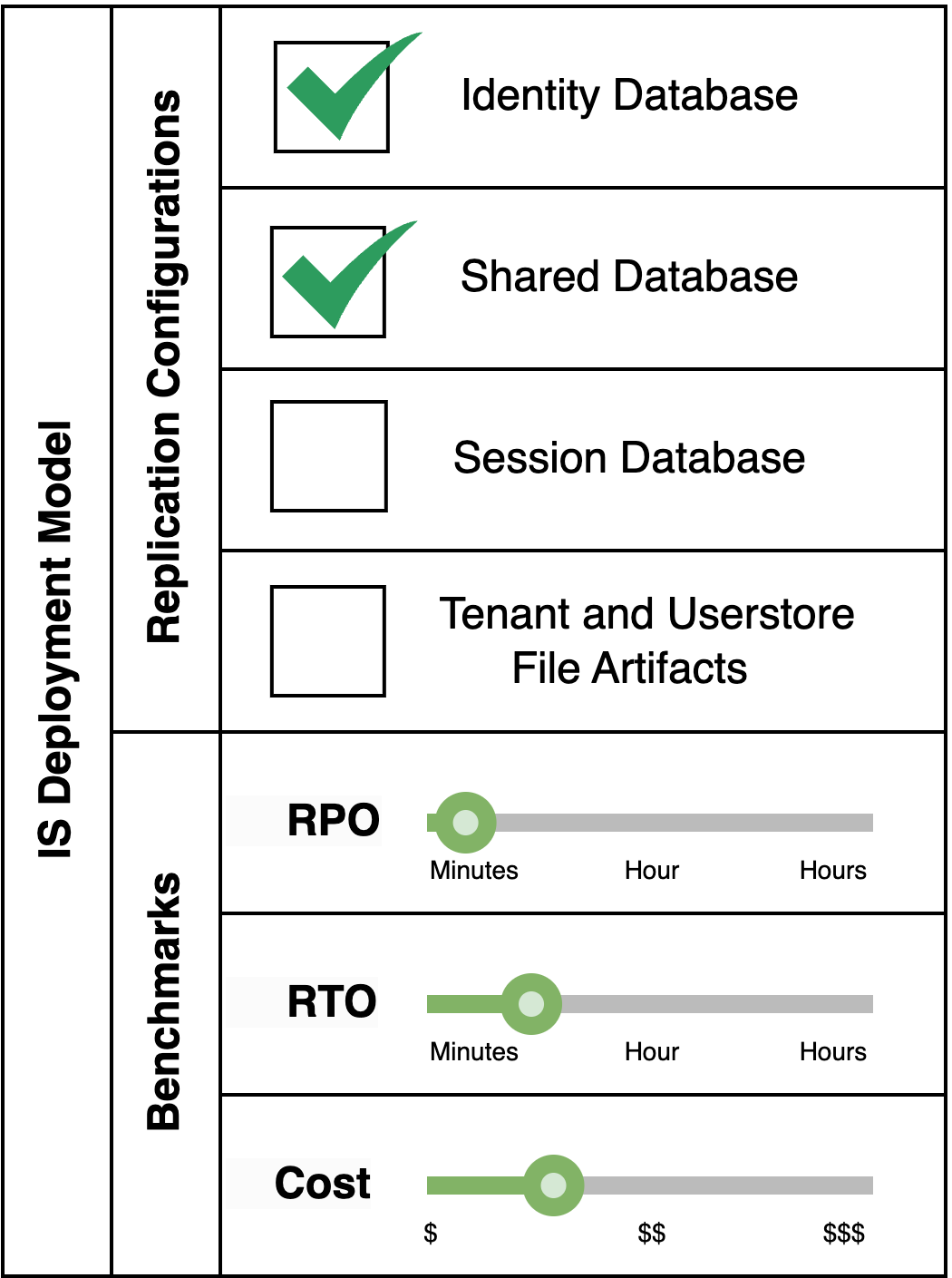
This pattern is suitable when a fully fledged Identity Server system which makes use of multi-tenancy and secondary userstores, and when retaining sessions is critical even in the event of a disaster, is required.
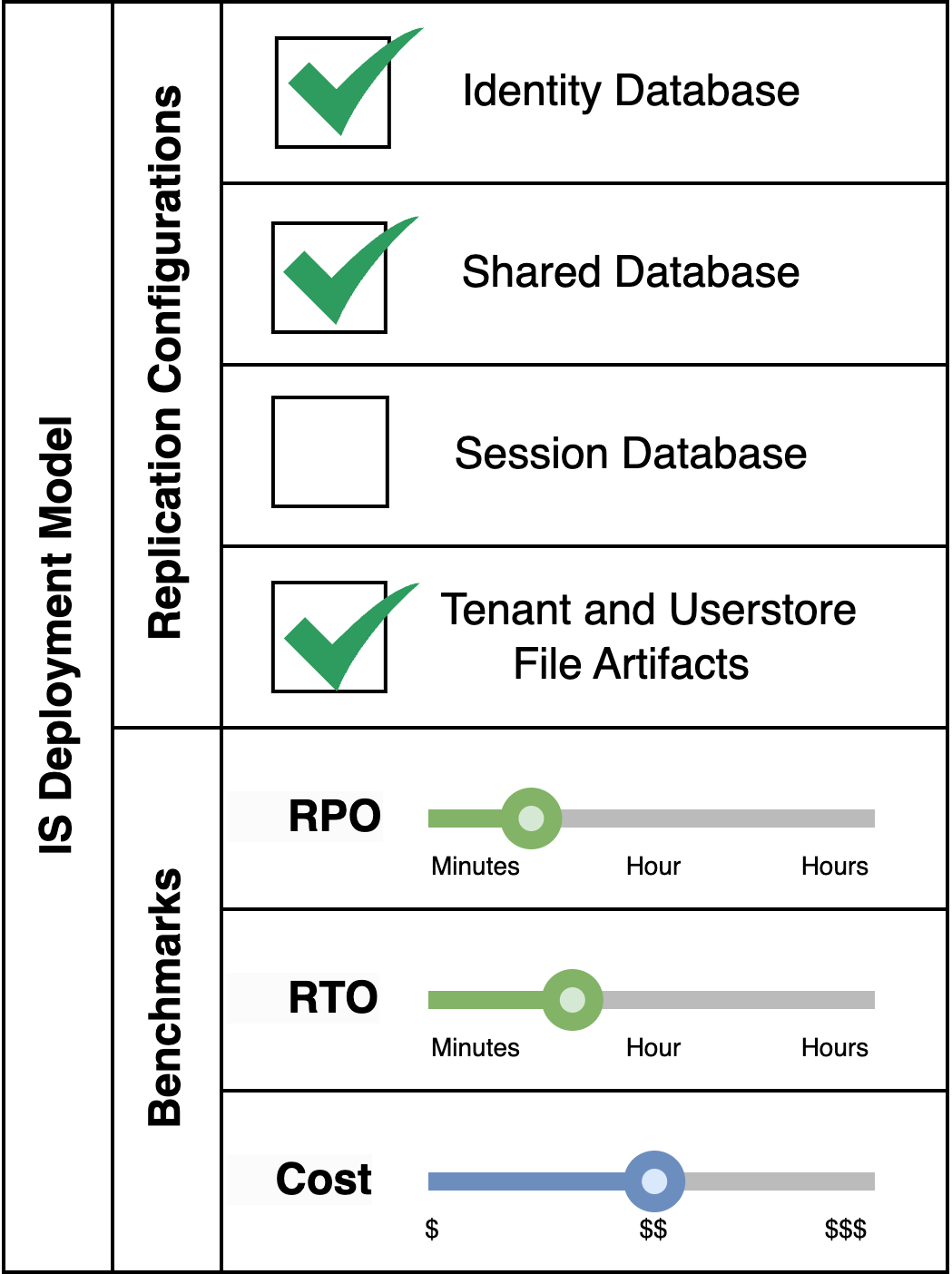
Pattern Variant 2: Disregard Session Database Replication
This pattern is applicable for a fully fledged Identity Server system which makes use of multi-tenancy and secondary userstores, where losing session data in the event of a disaster is deemed acceptable. This is the most commonly used pattern as it preserves all functionality of the Identity Server with good RPO/RTO values, and losing session data during disaster recovery, which occurs rarely, could be acceptable to most businesses.
Pattern Variant 3: Disregard File Artifacts Replication
This pattern is applicable for an Identity Server system which does not make use of multi-tenancy or secondary userstores, but session retention even during disaster events is critical.
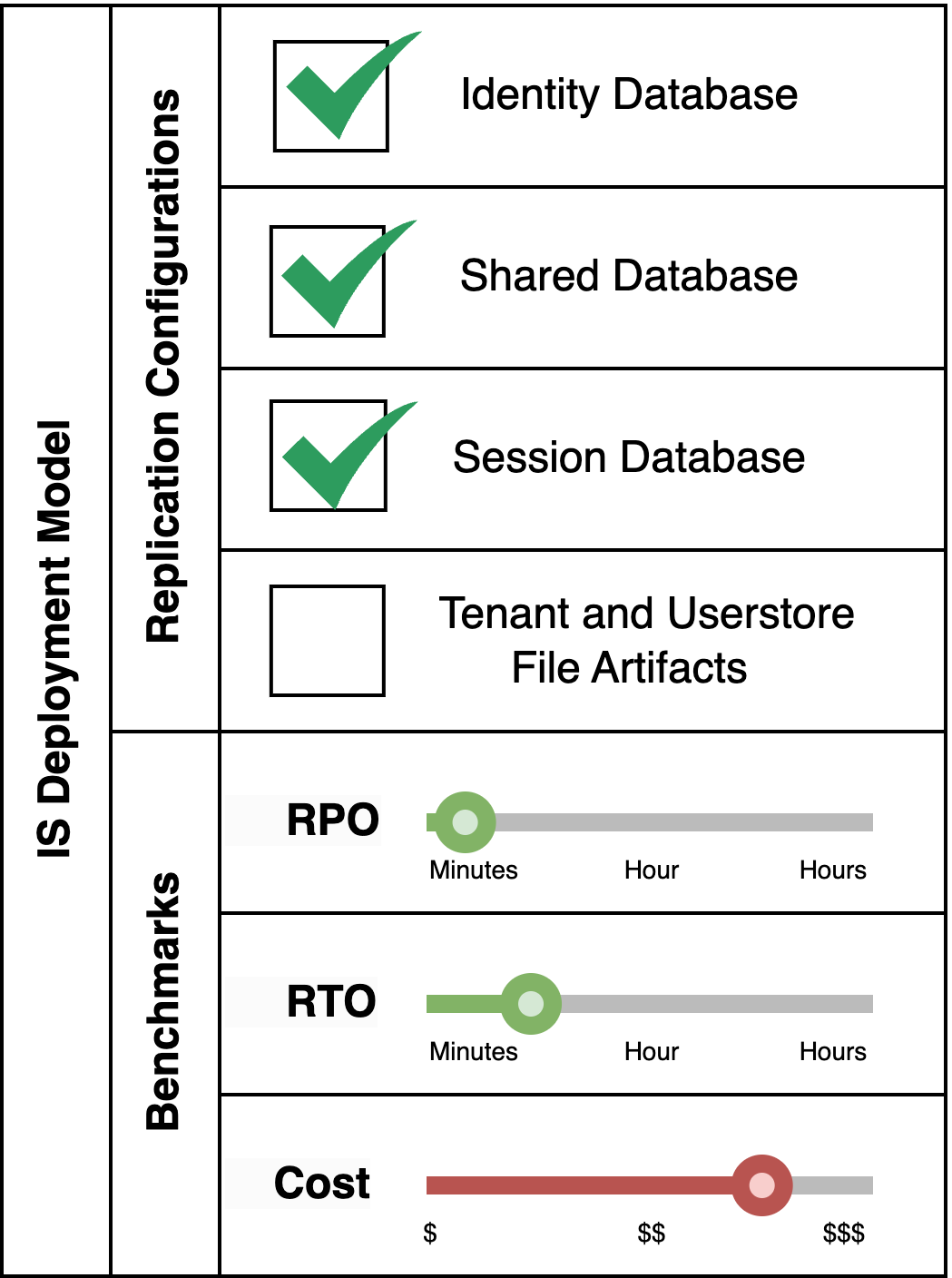
Pattern Variant 4: Disregard both Session Database and File Artifacts Replication
This pattern is suitable for an Identity Server system which does not make use of multi-tenancy or secondary userstores, and session retention during disaster events is not required. This is the cheapest option, and it also offers the lowest RPO/RTO values at the cost of some functionality.
Failover Completion¶
Once failover is triggered, scaling up the k8s cluster and starting the servers will consume about 5-10 mins, i.e. RTO + 10. After the databases, fileshares and clusters are ready, updating loadbalancer to direct traffic to the new DR region would take another 5 mins (RTO + 5). The diagram below shows the new state of the deployment once failover is complete.