Understanding Disaster Recovery in WSO2 Identity Server¶
In today’s rapidly growing digital landscape, businesses and organizations rely heavily on technology to power their operations. High availability and minimal downtime is a necessity for business-critical systems to run smoothly. In the event of a natural catastrophe like a hurricane, flood, earthquake, or a human-made crisis such as a cyberattack, prolonged system failures would most likely happen which could pose dire consequences on business operations. Hence, implementing disaster recovery mechanisms will be extremely beneficial to mitigate the effects of regional system failures. In case of a failure of the main deployment, it should be possible to transition a part or all of the traffic to an alternate region so that the applications can continue running. To implement Disaster Recovery (DR) strategies in an enterprise application system that is using WSO2 Identity Server, the Identity Server deployment should be set up in a way that enables synchronization of certain data and runtime artifacts, which will be explored in this document.
Key Terms of Disaster Recovery¶
In order to determine the type of deployment pattern required as per the business needs, the following metrics will be taken into consideration.
-
Recovery Time Objective (RTO) - The RTO refers to the maximum amount of time an application can be statistically expected to be offline.
-
Recovery Point Objective (RPO) - The RPO refers to how much data loss can be considered acceptable.
The values of these metrics are usually determined by the Service Level Agreement (SLA) between the service provider and the consumers. The SLA represents a commitment from the service provider to deliver a specified level of availability and outlines the consequences of failing to meet this agreement. Evidently, smaller values for RTO and RPO indicate a requirement for the application to recover quickly from disruptions. The exact specifications of the DR deployment patterns will depend on the RTO and RPO selected.
DR deployment patterns, which are analogous to High Availability (HA) patterns, define the speed at which a system can recover after a disaster. These patterns describe the processes and procedures that are in place to ensure that the system can return to normal operations in a timely manner. In essence, the RTO and RPO are key metrics in defining the expected service level during a disaster event which causes the primary system to fail.
Steps for Defining RTO and RPO Metrics for WSO2 Identity Server¶
1. Business Impact Analysis (Identify Critical Systems and Data)
Determine the criticality of WSO2 Identity Server to the business application and the impact of each data aspect (identity information, tokens, sessions, etc) on business operations. Identify the applications or systems integrated with the WSO2 Identity Server and critical to the business operations and determine the expected level of service for each one. The following questions may help in the analysis.
- Which applications are most critical to the business?
- How much of the critical business application functionality is dependent on the availability of the Identity Server?
- How frequently would Identity Server tenants and userstores be created?
- Should user sessions persist even in the event of a disaster?
2. Assess the Impact of Downtime
Based on the business criticality, determine the maximum downtime the organization can afford for each application or system. I.e. determine the potential impact of downtime on each critical system. This includes financial, operational, and reputational impacts. Also, determine the impact of the Identity Server being unavailable for running business applications. For example, an application may be able to provide some level of functionality without the Identity Server. The functionality of the application that does require a working Identity Server could also be crucial to the business.
3. Define RTO
Calculate the RTO based on the above information. The RTO is the expected upper bound of the time it should take to recover the application or system after a disaster. This value should be less than or equal to the maximum downtime defined earlier. Define specific RTOs for each critical system. For example, you might determine that your email system must be restored within 4 hours, but a less critical system can have an RTO of 24 hours. The RTO of the Identity Server may need to be aligned with the RTO of the most critical system.
4. Define RPO
Calculate the RPO based on the above information. The RPO is the acceptable amount of time during which the data might be lost. This value should be less than or equal to the maximum data loss the organization can afford. Define specific RPOs for each critical system. For example, it might be determined that customer identity data must be recoverable up to the last 15 minutes before the disruption occurred.
5. Select Appropriate Recovery Strategies
Pick suitable data replication services that can achieve your expected RTO and RPO and design a manual or automated DR switch process to meet business needs. Choose recovery strategies and technologies that align with the RTOs and RPOs. This may involve redundant systems, data backups, and failover solutions.
Deployment Architecture Basics of WSO2 Identity Server¶
The implementation of Disaster Recovery (DR) deployment for the WSO2 Identity Server can be achieved by following an Active and Passive region architecture as per the below diagram. In this architecture, the passive region deployment can be maintained in a cold state and activated in the event of a disaster.
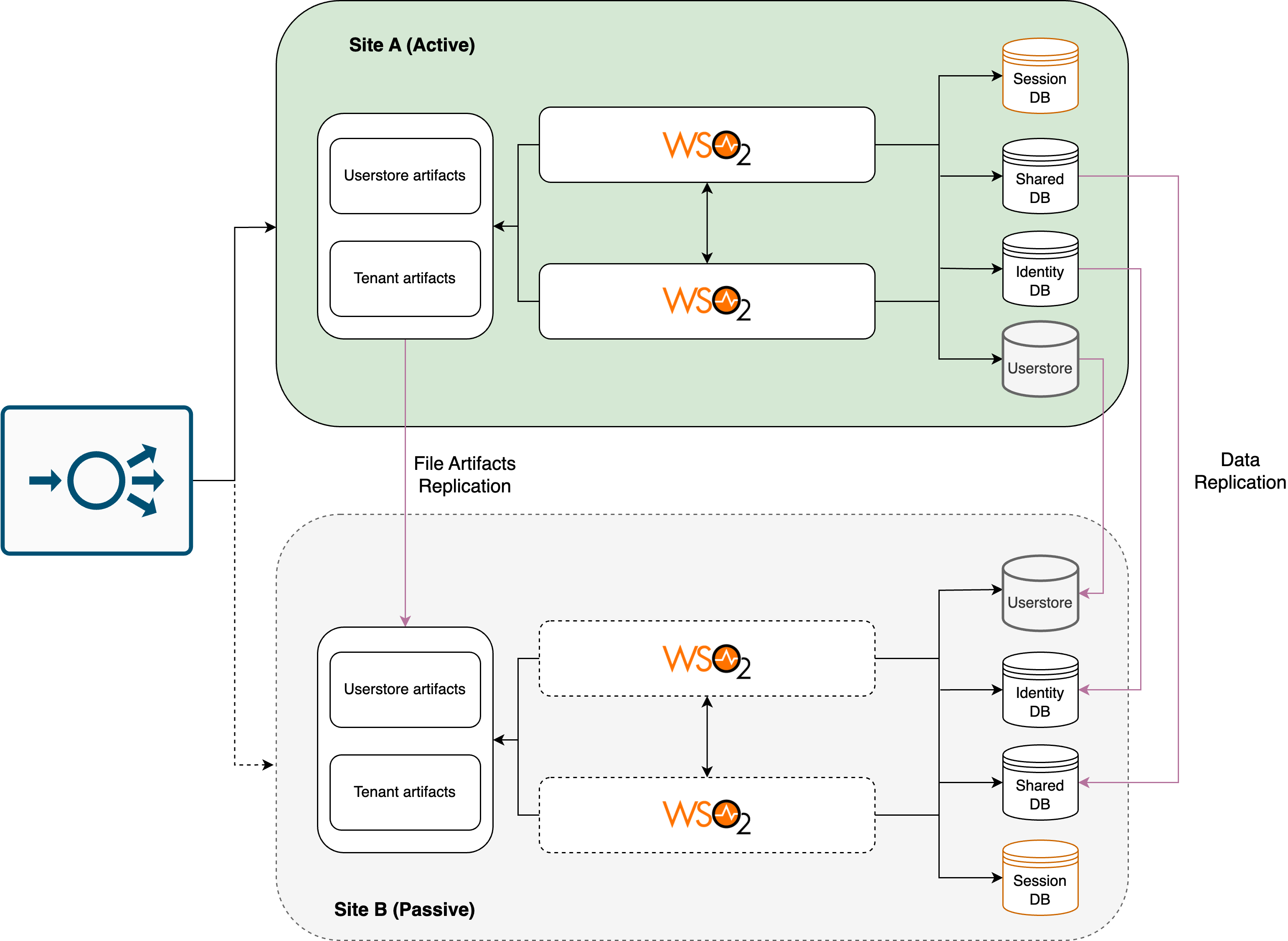
Usual Regional Operation¶
Region A region is the primary region, which hosts the active site where user traffic is actively processed. It includes the primary database server, primary filestores of IS runtime artifacts, and active Identity Server instances which accept all network traffic. Clustering and load balancing are set up for high availability within this region.
Region B serves as the disaster recovery site, remaining idle until needed. It includes the passive secondary database server and secondary filestores, which are read-only replicas of their primary counterparts. Data from the primary database server and filestores are replicated to the secondary database server and filestore respectively in the passive region to ensure data consistency. The Identity Server instances remain downscaled and idle in this region until a failover occurs.
Important
- To ensure all necessary runtime file-based artifacts, such as user store configurations and tenant configurations, are replicated to the passive region, a file artifacts replication service should be utilized in the deployment process. To learn more about file artifacts in a WSO2 Identity Server deployment, see here.
- Additionally, databases must be replicated using a geo-replication service to the passive region.
- It is also important to note that any user stores utilized by the enterprise, such as Active Directory or LDAP, must be replicated accordingly to the passive region.
Failover and Recovery Operation¶
When a disaster or failure occurs, causing the primary region to become unavailable, the failover mechanism is triggered. Traffic is redirected to Region B, and Identity Server instances that were passive become active.
In the event of a disaster, the WSO2 Identity Servers and the other required services in the disaster recovery (DR) region must be manually activated, and traffic must be redirected to the DR site until the primary region has fully recovered from the disaster as per the below diagram.
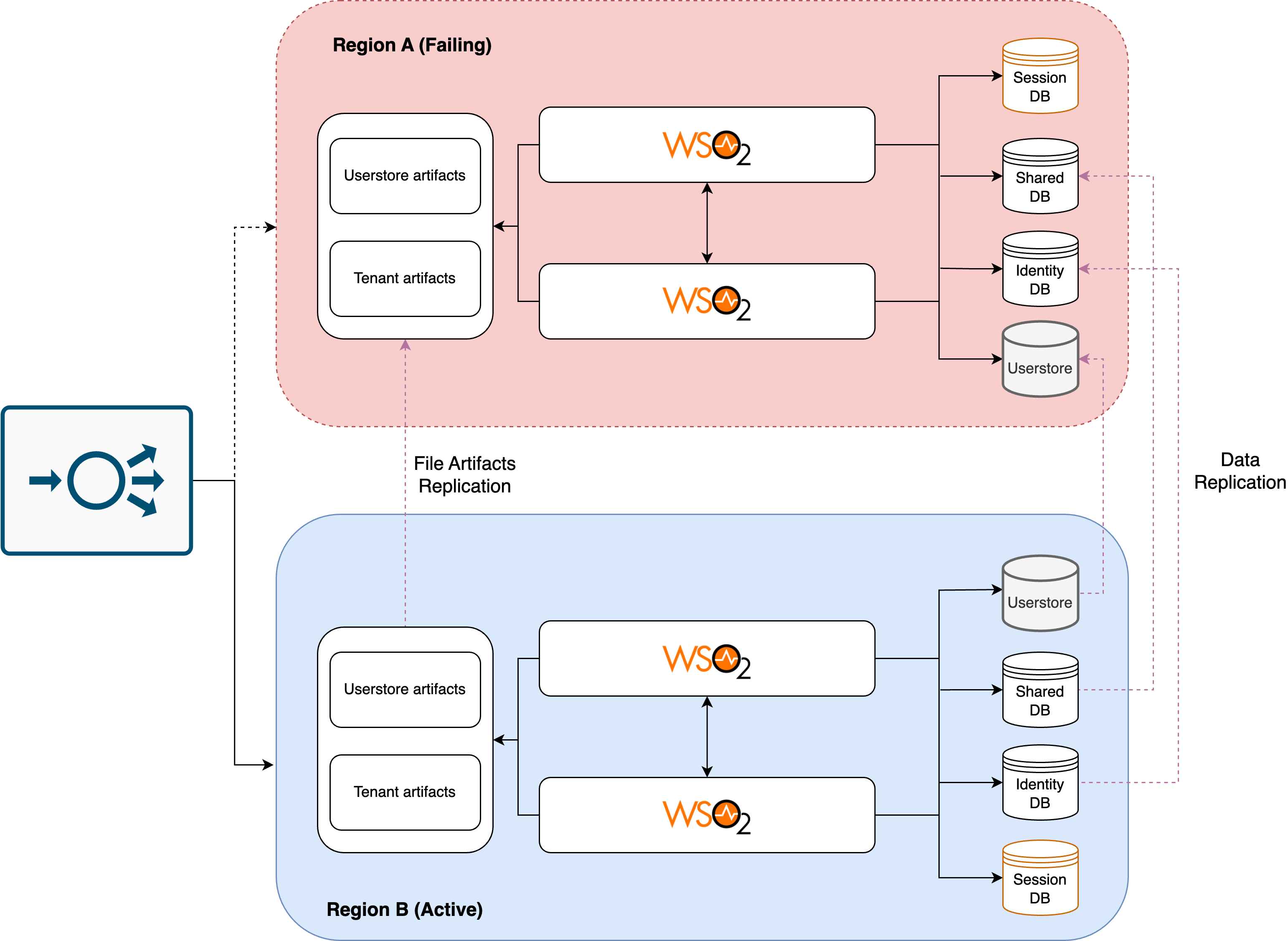
To ensure a seamless disaster recovery process, it is important to properly configure and test the manual trigger mechanism for starting the servers in the DR region. In order to maintain the consistency of data and runtime file artifacts, the data replication and file replication services should be configured to switch the replication regions as depicted in the diagram. This is to ensure that the latest data and file artifacts are synced to the primary region.
After the primary region has fully recovered and all services are operational, the traffic can then be redirected back to the primary region from the DR region. It is important to regularly test and review the DR deployment to ensure its success in the event of a disaster.